Welcome to the Norwegian Blue Parrot project. It is a series of websites for demystifying AI and Deep-Learning through jovial, in-depth descriptions, fun interactive, and a touch of geekiness.
Select Language 
Introduction

Welcome to the first "Norwegian Blue Parrot" project website. For each AI project, I write the code and show you how it works. You can test it using a mobile phone, tablet, and laptop. Furthermore, you can see for yourself the effectiveness and the shortcoming of each AI model.
I have developed dozens of AI projects, and with each AI model, I learn a bit more insights into the world of Artificial Intelligence.
The audience or point of view (POV) for demystifying AI is primary for AI enthusiasts and friends with a curious mind. However, I am a full-stack programmer, a solution architect, and an AI scientist, and therefore, I will not shy away from the math and the coding, but I will remain steadfast to the primary POV.
Before digging into the technicalities, we will have fun test-driving the AI model. After we have a firm grasp on "what" we are trying to demystify, we will travel a full journey from coding to gathering the data. We will take a break to understand the particular data biases , both the conscious biases and the unforeseen consequences. We will reach the journey conclusion at the use-cases, i.e., what is the purpose of this AI project, and what other possibilities could this AI model can be used either ethically or feloniously.
So if you are ready, let's take a collective calming breath … … and begin.
-- LaVar Burton Reads (paraphrase)
The "k2fa" AI project is for kids to learn about farm animals. Think of "k2fa" as kids wandering through a farm and naming the animal that they see.
More concisely, "k2fa" is Deep Learning Convolutional Neural Network (CNN) image classification model.
Before charging ahead with an in-depth explanation, let's test the "k2fa" kids. Show the "k2fa" kids a picture, and they will identify it. Scroll down to the "Prediction section" and have fun.
Prediction

Hello, from "k2fa" kids. Since "k2fa" kids are not robots, you are selected to be the avatar , i.e., the hands and feet of the "k2fa" kids.
Imagine yourself as a "k2fa" kid, walking around the farm, taking photos , or uploading them using iPhone, Android phone, tablet, or laptop. This website is mobile-friendly.
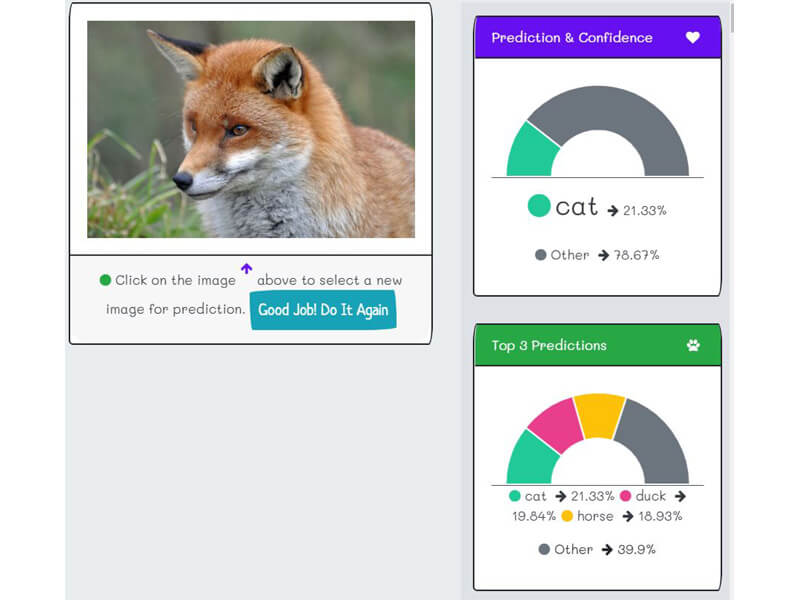
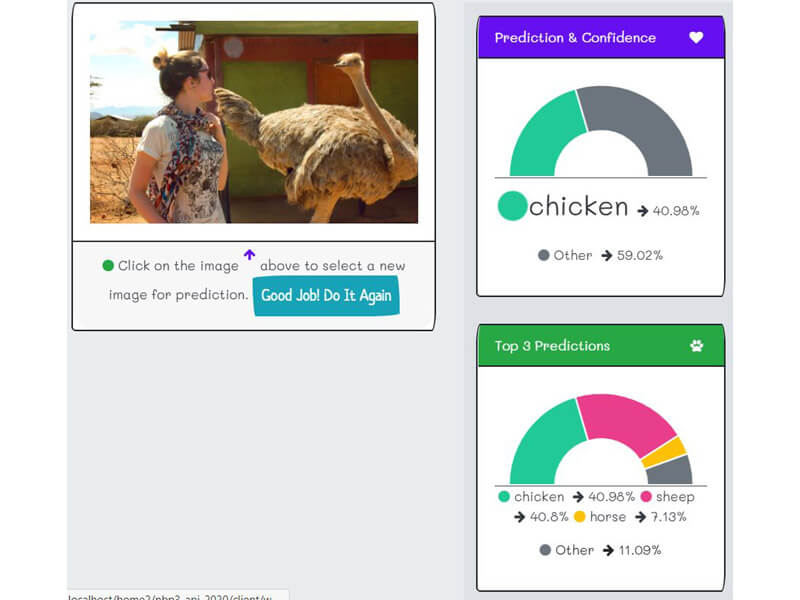
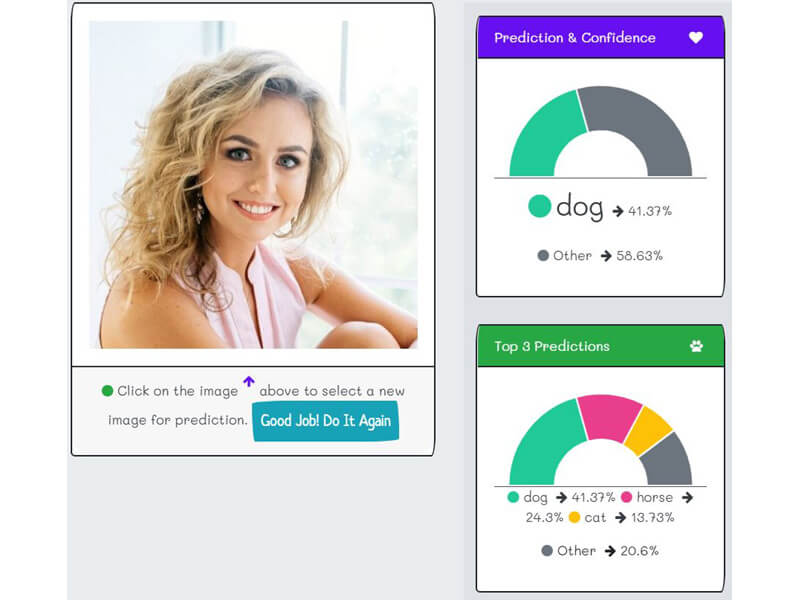
Take a picture or upload an image of a dog, a chicken, a cow, a wolf, your face, your friend, or even an armadillo. The "k2fa" kids will immediately identify which of the thirteen farm animals is the closest match to the image, including the confidence level. Furthermore, the "k2fa" kids will show the top three inferences.
One should run the test many times. It will give a clear understanding of what is possible and what is not.
There are copious statistics that accompany each inference. The in-depth explanation for the statistics, data, insights, biases, and limitations will be in the next section, but for now, enjoy being a "k2fa" avatar.
*Please note that when the Google App Python engine is in "Idle" mode, it will take an extra 25 seconds to load up. It will display "Active" when ready, and it happens only once. The engine will go back to "idle" mode if no API request for in the last 15 minutes. It is a scaling feature to save money when no one is accessing the API server.

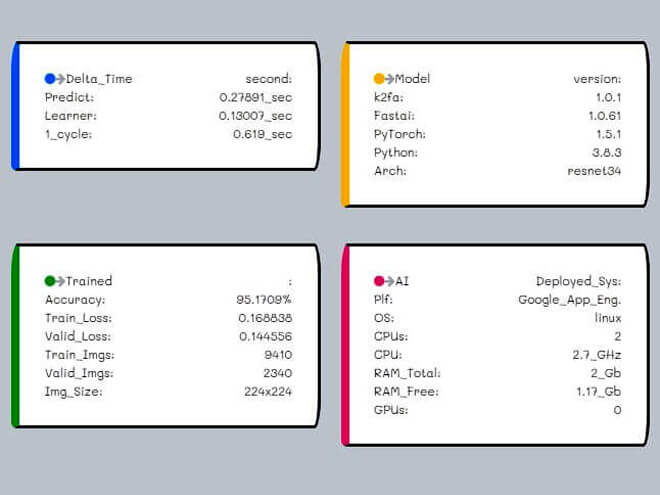
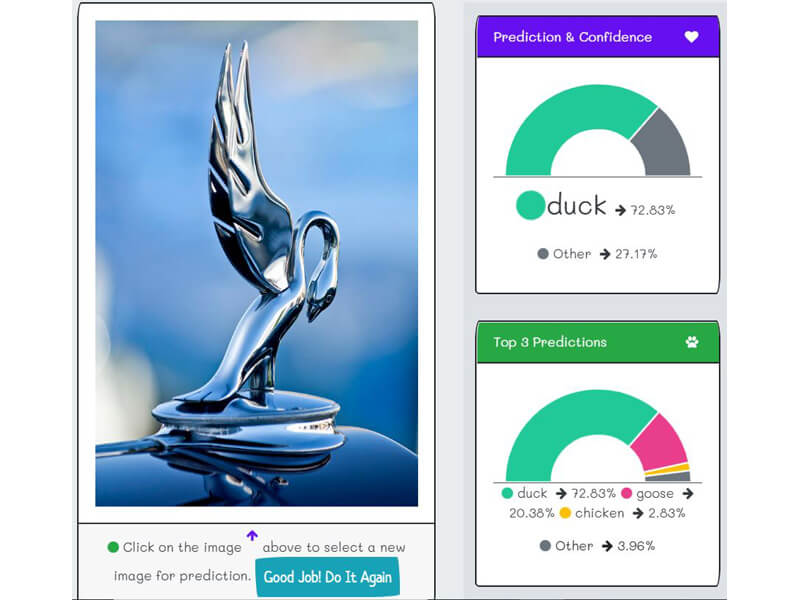
Cat 80.2%
Other 19.8%
Cat 80% Cat 80% Cat 80%
Other 19.8%
Legends:
- The "Predict" time is the principal value. It calculates the time "k2fa" takes to give a prediction. On average, during high system-load, it is less than half of a second.
- The "1_cycle" time is calculated from a moment the device, e.g., iPhone or laptop, issues the request to it received the response from the server. It includes the network time, image upload, and JSON API response time.
- The "Architecture" section will explain the timing in-depth.
The "Model version" shows that the AI model dependents and its software version. The "Model" section will give a full explanation.
The "Trained" describes the "k2fa" training statistics. The "Model" and the "Data" section will explain it further.
- It is comparable to a "microservices," and it is not the massive AI training server.
- There is no GPU , and the CPU RAM is only 2 GB. The reported "free RAM" for each request is for monitoring memory leaks.
- Google App Engine enables auto-scaling automatically.
- The "Architecture" section will fully explain it.
The "Raw inferences" is raw data response from the API. It contains the thirteen possible farm animals and the associate level of confidence.
Deep Learning CNN Model

The Deep Learning convolutional neural network (CNN) model is like the donut of the AI discipline. It's easy. It's sweet, and it is the go-to solution for image classifier problems.
The following is not a step by step instruction, but it covers the essential notes for an AI scientist to replicate the model independently.
Occasionally, the AI discipline uses specialized terminologies that impede the understanding of simple concepts. It is a bad practice because it encourages the memorization of vocabulary rather than original thinking. In other words,
A rose by any other name would smell as sweet
-- William Shakespeare
"AI" and "Deep Learning" are the two terminologies that worth more in-depth explanations.
Artificial Intelligence (AI) has no formal, concise, or verifiable universal accepted definition. The popular interpretation is "a machine or a program that mimics cognitive functions and algorithms."
From Ada Lovelace's programs for Charles Babbage's Analytical Engine in the 19th century to the 1949 IBM-701 Checker program by Arthur Samuel to Apple's Siri, they can all be classified as AI.
The fuzziness is the level of complexity in the algorithms, i.e., how complex does the algorithm has to be for it to be considering as an intelligent machine? Is human the only intelligent creature on earth? Does everyone on the planet have the same innate intelligence?
Furthermore, in movies, books, and social media, there is an overlap between "consciousness" and "intelligence." Being conscious does not imply being intelligent, and having intelligence does not mean having consciousness.
For example, a dog has awareness but can't do the math , and the Apple' Siri program can do trillions of calculation per second but can't feel happiness .
To demystify AI, from this point onward, any machine algorithm that has more than one trillion calculations will be anointed as "Artificial Intelligent."
"K2fa" model has an estimate of 2.7e-14 calculations per fit-cycle, and therefore, "k2fa" is an AI.

"Deep Learning" is a sub-field of the AI discipline. It's loosely model after the inner working of the brain neurons, and hence the innovative name "convolutional neural network" (CNN). It based on the "universal approximation" theorem (UAT).
The awe-inspiring truth is that this one theorem can tell the difference between a cat and a dog, skin cancer cells from healthy cells, classifying dozens of objects in a picture, identify tweets sentiment, recommend movies, predict sales, and thousands other related tasks in four classifications. They are image classifier, image segmentation, natural language processing (NLP), and prediction using tabular data.
The "awe" in the awe-inspiring is that the UAT does not need to understand the causality. In other words, the UAT does not use rules-based logic, such as a cat does not have feathers or a cow has four legs.
"K2fa" model is built on the fantastic "fast.ai" library by Jeremy Howard, Rachel Thomas, and Sylvain Gugger. The goal is for an AI scientist to have essential information to replicate the "k2fa" model independently. The salient point is that it is just math and coding, no magic. The recipe of the "k2fa" Deep Learning convolutional neural network image classifier is as follows.
1. Collect data
- The full description of collecting data is in the "Data" section below. The steps are as follows.
- Go to the farms to take pictures and videos.
- Search and download non-copyright images using Google image search, Instagram, and Facebook.
- Use the "Download All Images" app, a Chrome extension by Mobile First.
- Separate the images into one of the thirteen farm animal folders.
- True to form, the data collection takes most of the time in this project.

Collect
2. Clean data
- Verify each image in the correct folder.
- Write python scripts to resize, crop, and center each image to 224 by 224 pixels.
- Write python scripts to rename filename to be "chicken1.jpg", "chicken2.jpg", etc. It is optional, but it helps.
- Write python scripts to split each folder to have sub-folder-image "train" and "valid."
- Each folder contains a different number of files, e.g., the rabbit-folder has 612 images, while the dog-folder has 1028 images. Therefore, splitting 20% per folders for "valid" is fairer than randomly allocating 20% overall for validation.

Clean
3. Calculate the Data-Bunch mini-batch size
- Query the cloud-server (Google Colab-Pro) for CPUs (4), available RAM (24 GB), GPUs (1), available GPU-RAM (16 GB). Refer to Predict section above.
- Verify all trained images are 224 by 224 pixel. The total images are 11750.
- The calculated batch-size is 64 .
- The reason for using mini-batch and stochastic gradient descent (SGD) is because to train all images in one-cycle takes more GPU RAM than most cloud servers have available.
Mini-batch & SGD
4. Create the Data-Bunch
- Create "fastai.vision.ImageList" from ".from_folder()" command.
- Separate the "train" from "valid" by doing ".split_by_folder(train='train', valid='valid')" command.
- Assign the label from the folder-name, i.e. using ".label_from_folder()" command.
- Increase the number of train-images with data-augmentation using "fastai.vision.LabelLists.transform" command.
- Create the data-bunch using the fast.ai method. Using ".show_batch()" command to verify the data-bunch is correct.
- Use "fastai.vision.imagenet_stats" command for image normalization.

Data-bunch
5. Find the fit-rate
- Calculate the fit-rate using fast.ai method ".lr_find()" and ".recorder.plot()". It is based on "How Do You Find A Good Learning Rate" by Sylvain Gugger.
- Look for the lowest point and take 1e-1 less, or write a python scripts using the ".recorder.losses" to calculate the average 12 points slope that less than 1e-2 and divide it by 10.
- The resulting fit-rate is "slice(0.00030935651031245543, 0.004833695473632116, None)"
- It is usually close to professor Jeremy Howard's magic fit-rate of 1e-3.
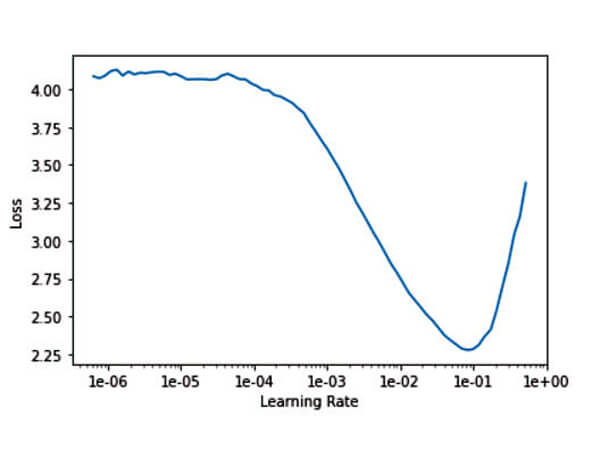
Fit Rate
6. Use the default hyper-parameters
- The "percentage per one_fit_cycle" (pct_start) rate is 0.3.
- The "momentum" rate is list(0.95, 0.85).
- The "dropout" rate is 0.5.
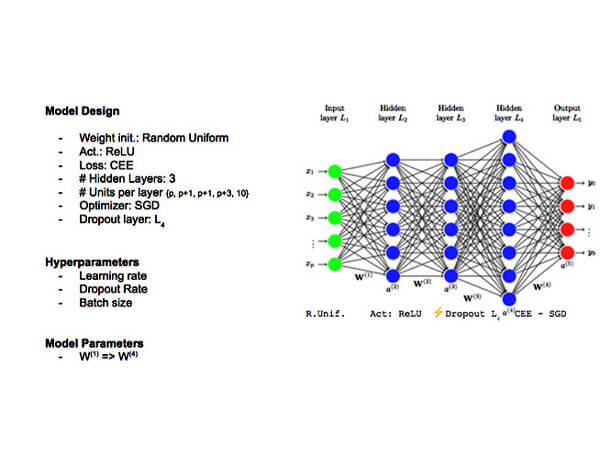
Hyper-P.
7. Select the base architecture
- The base architecture is "resnet34." The "resnet50" would work as well.
- "Transfer learning" is a method using the pre-trained convolutional neural networks to train an image classifier model faster and with higher accuracy. The ILSVRC trained the "resnet34" or "resnet50" model with 1.2 million images over 1,000 categories.
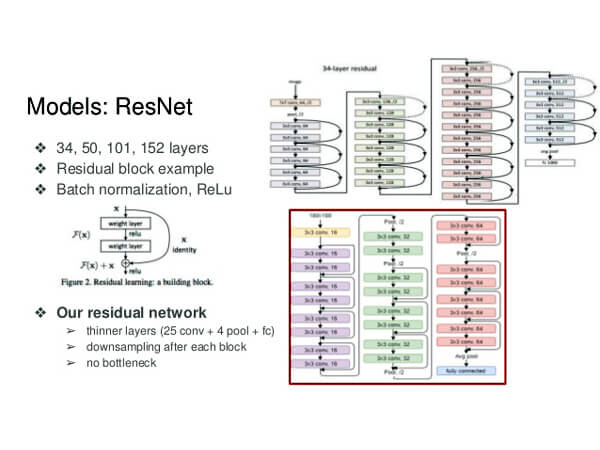
Reset-34
8. Train for six epoch
- Train with "fastai.vision.fit_one_cycle()" method.
- fit_one_cycle is better performance in speed and accuracy, over the ".fit()" method.
- Select the "CrossEntropy" as the accuracy measurement.
- The resulting accuracy is 0.955556
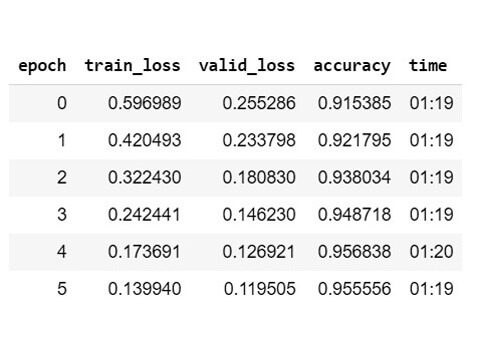
95.5556%
9. Unfreeze the model
- Unfreeze the model to train all the layers. By default, the resnet34 layers are frozen.
Unfreeze
10. Find the new fit-rate
- Perform the same step as #5.
- The resulting fit-rate is "slice(3.7192832996602014e-06, 5.811380155719065e-05, None)".
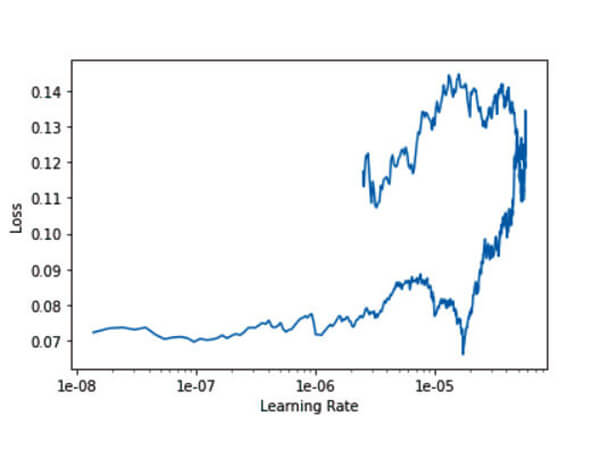
Fit Rate
11. Train for six more epoch
- Perform the same step as #8.
- The resulting accuracy is 0.967949
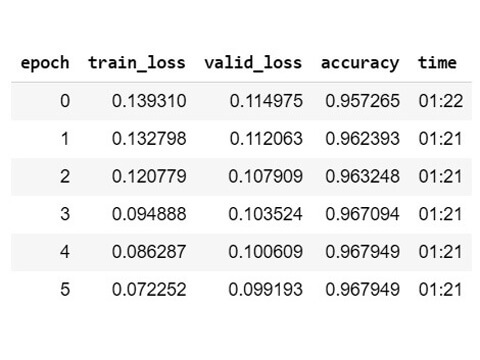
96.7949%
12. Verify the loss and confuse matrix
- The most confused is between "duck" and "goose" then "sheep" and "goat" then "horse" and "donkey."
- Additional epoch training would help to increase the accuracy a little more because the train-loss and valid-loss are decreasing.
- Additional images would be the best method to improve accuracy.
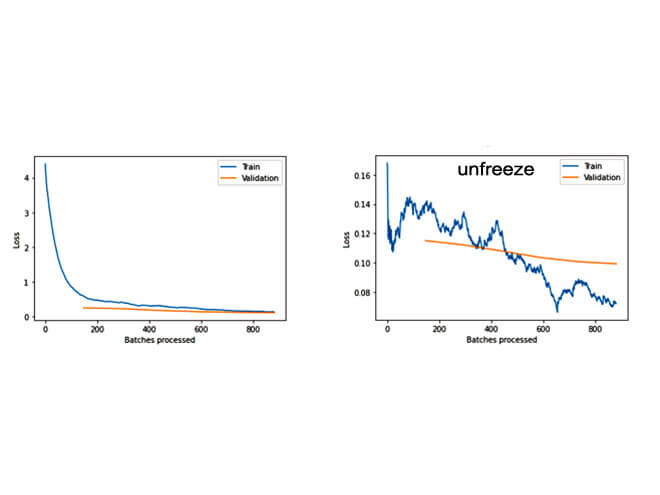
Loss & Confuse
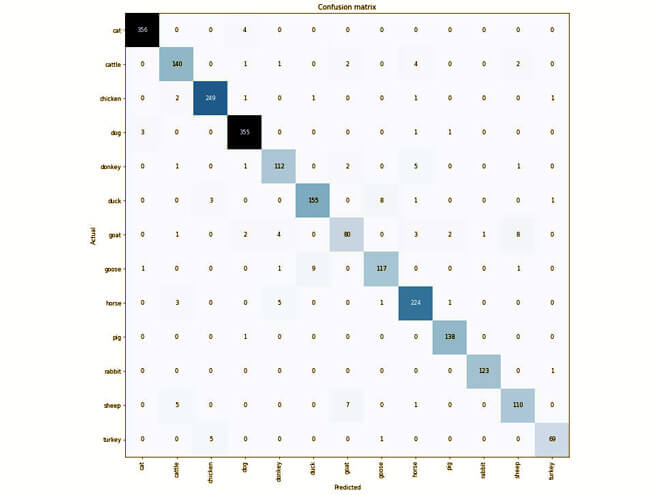
Loss & Confuse

Loss & Confuse
13. Deployment
- The deployment is on the Google App Engine API microservices. The development of this beautifies client-website follows the same architecture as the "Be-Nice-2020" project.
- It is an enterprise-grade deployment at little or no cost using microservices and CDN. Be-nice-2020's architecture is a well-written architecture, including step-by-step instructions. The difference is that the Google App Engine is a Python engine and not the NodeJS engine.
- The "k2fa" inference model is the export file from "fastai.vision.learn.export()" command. It enables the model to "predict" without the need for massive servers and GPUs.
Deployment
The Data

For a deep learning project, the accuracy and the perceived usefulness of the AI model is due in large part from the size of data, the accuracy of labeling, and the biases both intentionally and adventitiously.
"K2fa" uses the following checklist . The steps for training "k2fa" is comparable to other image classifier models, and therefore, the list is suitable for most AI projects, such as:
- identify endangered species,
- identify sickness in chicken flocks,
- identify distracted drivers,
- identify real or fake Nike shoes,
- identify automobile make and model,
- identify between Sunni and Shiite Muslims (controversial project),
- identify potential criminals in a shopping mall, i.e., before committing the criminal act,
- and identify skin cancer cells.
- There will always be discord among AI scientists, domain experts, and end-users about what should or should not be in the data. The goal is to have a balance between technical requirements and the project objectives.
- A data discussion is essential to the AI model's success. The debate is highly desirable at the project "envision" phase and include all parties.

Common Sense
- Project managers, who are new to AI, always underestimate the time for data collection and data cleaning. They are steps #1 and #2 in the "Model" section.
- On average, the allocation time should be 45% to 65% of the project schedule.
- The "k2fa" data collection and cleaning took about six weeks. It is on the higher end of 65% because the domain experts can't drive themselves to the farm.
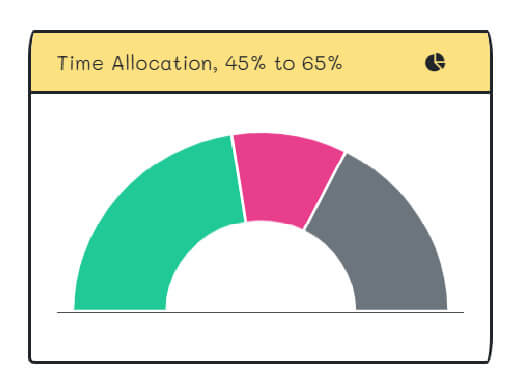
Time
- Subject domain experts are people that know how to label the data correctly. For example, for "identify skins cancel cells," a dermatologist is a top choice, and for "identify sickness in the chicken flocks", it would be a chicken farmer or a veterinarian.
- For a subject that requires research, an analyst, a librarian, or crowd-sourcing is preferable. For example, "identify a person age" is ideally suited to use crowd-sourcing, or "identify major cities by partial aerial photographs" requires a herculean researching effort, so an analyst or a librarian is a top choice.
- For "k2fa," the subject domain experts are two impetuous eleven and thirteen-year-old kids . They have the energy to run around the farms taking photos and videos. They are wiz when it comes to searching on social media, and they can label the images at a dizzying speed. Furthermore, kids are the experts to judge which farm animal pictures are valid or invalid.

Experts
- The goal for the "k2fa" AI model is 94% accuracy, using the standard "CrossEntropy" equation. A rule-of-thumb is 94% accuracy, or higher, is designating as a world-class AI model.
- The project goal is to have a mobile app accessing the "k2fa" as an API REST microservices. The target API response time is 0.5 seconds or less. The response target time is the same as enterprise-grade REST API microservices.
- The "k2fa" budget for collecting data-images is equivalent to the cost of pizzas, atomic hot chicken wings, and boba-teas.
- The original schedule for data collection is for three weeks, but the actual is six weeks.

94% Accu. & 0.5 sec.
- The data-image size is 224 by 224 pixels. New images must be resized, cropped, and centered. Initially, it was 448 by 448 pixels, but after a few training cycles, the smaller size is sufficient.
- The thirteen farm animals are cat, cattle, chicken, dog, donkey, duck, goat, goose, horse, pig, rabbit, sheep, and turkey.
- The goal is to have 1,000 images per category. Since ILSVRC trained the "resnet34" model with over a million pictures, the "k2fa" leverages the pre-compute weights, and therefore, does not require hundreds of thousand images.
- The actual is an unbalanced number of images per category, e.g., the cat-folder has 1036 files while the rabbit-folder has 738 files.
- The image must be relatively centered. Collectively, they represent the animal in a different setting and different perspectives, e.g., cat in a chair, cat in the barn, cat grumpy face, cat buttock, or cat in a reindeer costume.
- If there is a disagreement in the data-images, the domain experts will decide.

Valid

Valid

Valid
- The subject domain experts define valid and invalid image guidelines at the beginning of the projects so that others can help.
- Stock photos are invalid.
- Photographers take pictures in a controlled setting are invalid.
- If using all stock-photos, then the model might converge to higher accuracy. However, from the "objectives #4" above, the images are invalid because it is not how kids would take a photo on their iPhone walking around a farm.
- If two or more pictures look similar, then take only one. For example, when slicing images from a video feed at 24 frames per second, there is one, two, or three images per second that are sufficient difference.
- Photos with animals far away or too fuzzy are invalid.
- Pictures with multiple farm animals in one frame are valid; only if there is an intended animal in the foreground, otherwise they are invalid.

Invalid
- The "train data-image set" is for the model to learn, and the "valid data-image set" is for the model to compare for accuracy.
- Rachel Thomas wrote an excellent article, "How (and why) to create a good validation set," on how to choose a valid data set.
- A rule of thumb is setting aside 20% of the data-images for the validation set.
- Some of Kaggle's competitions use "valid," and "test" data set interchangeably. In this series, the "test" is different from the "valid" data set.

Valid & Train
- The domain experts or the AI scientists do not create the "test" data set. Unlike the "valid," the "test" is not part of the AI model development process.
- It is not an AI Kaggle's competition; therefore, the "test" is to validate the overall project goal and not limited to the AI model testing. Refer to the "Objective #4" bullet-point.
- The "test" data set is a sample of the real-world photos uses during the user-testing phase. It can be any pictures, such as, cat dress up as a dog, wolf, selfie, tree, or hamburger. The salient point is that the domain expert or the AI scientists would not have thought of using these pictures.
- The purpose of the "test" is exposing the AI model intentional biases and adventitious biases.
- The "test" will reveal the model generalization outside the "farm" setting, e.g., a picture of a dog walking in a city, an indoor pig, or a sculpture of a horse.
- As relevant as the "test" to the project goal, the result does not discredit the model calculated accuracy using the "valid" data set.
Test
- The discussion of biases is vital to the success of the project, see "Objectives #4", and it can be a fun mental exercise, but it is often overlooked.
- The next section is devoted to intentional biases and adventitious biases.
False Positive
- Convolutional neural network (CNN) is excelling at generalization. It can correctly identify images that are not in the "train" or "valid" data-set.
- In comparison to rules-based logic or traditional image pattern recognition software, it is a quantum step forward. Before CNN, the image classification problems were deemed unsolvable.
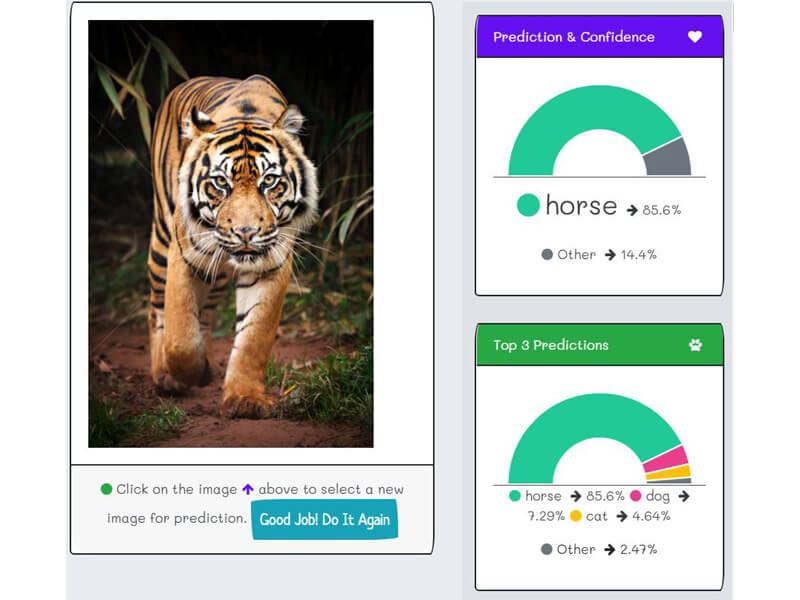
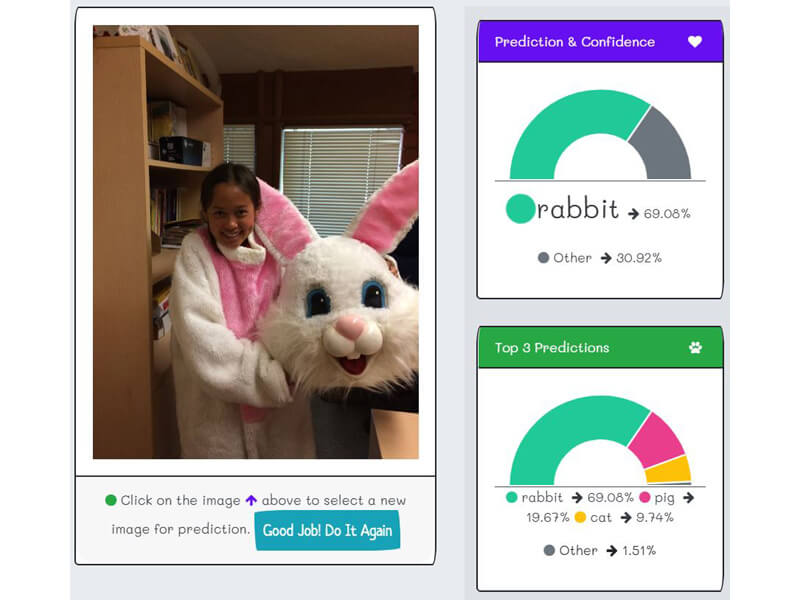
- "K2fa" can correctly identify photos where the farm animal is not prominent.
- For example, from the real-word user-testing, "k2fa" can correctly identify a neighborhood cat, a picture of Jenifer walking her dog, Ashley in a bunny suit, and a car-hood ornament. That's a fantastic generalization. It exceeds the AI scientist's dreams.
Generalization
Generalization
Generalization
- One of the most common and most significant mistakes that software project managers or even software solution architects did is to use the "agile software development" methodology for managing an AI project.
- In other words, one cannot gather a little bit of data and train it. It is because the model accuracy will not be able to converge. Furthermore, one cannot collect a few categories, e.g., "chicken" and "dog," train it, and expect the model to converge the same when added more classes.
- AI model development is not a "waterfall software development" methodology. It is not collecting the data and never revisiting it except for in a competition where one cannot alter the data.
- The data revisiting happens during the training session optimization, e.g., in "k2fa" the data image size is reduced by half after the first few training sessions.
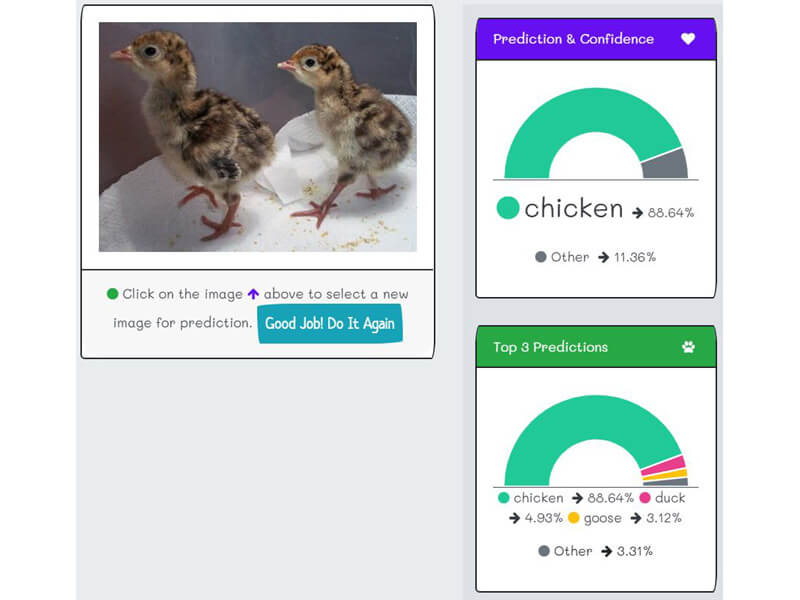
- The AI biases will force the resample of data. For example, in "k2fa", the data should be augmented with baby turkey pictures. A "poult" is a young domestic chicken, turkey, goose, pheasant, or other fowl, so the baby turkey does not a cute name like "chick" or "duckling."
- Another reason for data revisiting is dealing with false-positive. For example, in "k2fa", one could add a new category "tiger," and therefore, "k2fa" will not identify tigers as horses.
- The salient point is that the resampling of data does not imply resulting in better accuracy. The accuracy could suffer from new and resampling data.

Revisit
Biases

Biases exist in all data, even data from Kaggle's competitions. The reason is that people are different from nationality, religion, economic level to education. One group will say the data is fair, while other groups say the data is bias.
The goal is not to achieve data without biases, but data with the intentional biases listed in a "readme" document accompany the data.
"K2fa" is an anodyne subject. The resulting AI model and the app will not provoke a strong adverse reaction, but the data contain intentional biases. The domain experts and the business analysts are the best people in the project to list the intentional biases.
Even data is given in a competition. It is always a fun mental exercise to spot the biases in the data.
If this journey is about "identify between Sunni and Shiite Muslims" AI project, then understand biases are vital to the success of the project. However, the process of understanding the biases is the same. The "k2fa" intentional biases are as follow.
- "k2fa" predicts all baby fowl as "chick" or "duckling." It is because the farm and online search do not have baby turkey or baby goose. Cute, yellow and fluffy chick and duckling pictures are easy to get, but what about baby turkey? They are cute too.
Intentional Biases
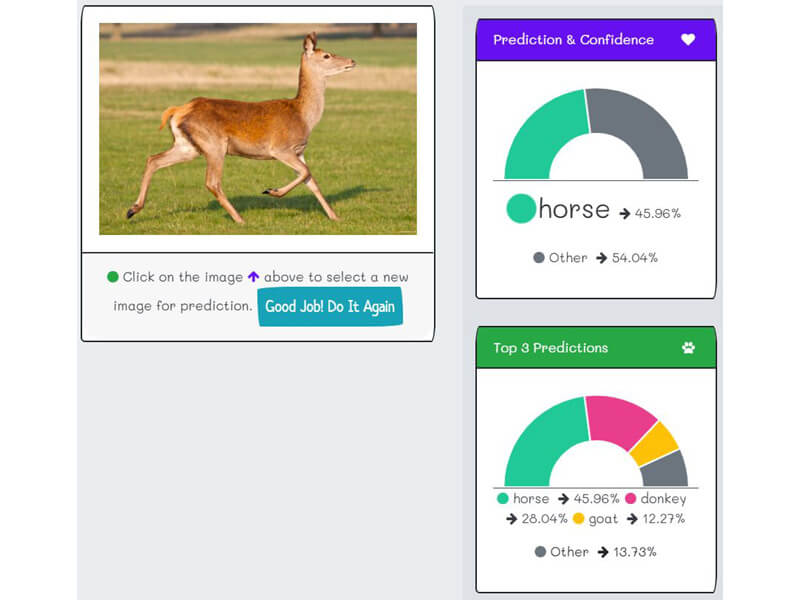
- "k2fa" predicts any graceful in-motion running donkeys or bulls as horses. It is because the data-images have only horses in a graceful motion and never a donkey.
Intentional Biases
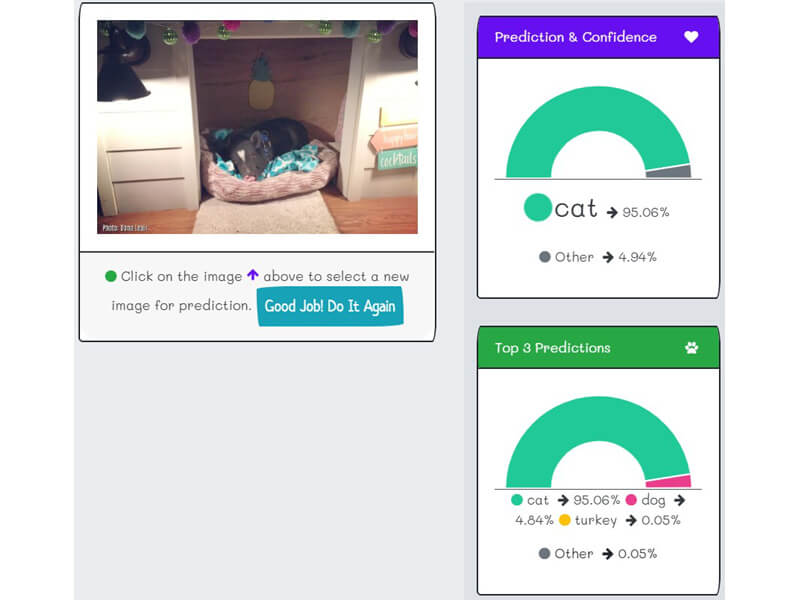
- "k2fa" predicts indoor pictures as dogs or cats, where the animal is a minor portion. It is because the data has the majority of indoor pictures with cats or dogs.
Intentional Biases
After user-testing, the adventitious biases emerge with fascinating discoveries. As before, if this journey is about "identify potential criminals in a shopping mall, i.e., before committing the criminal act," then the unforeseen consequences in the biases would be catastrophic. Never the less, the process is the same. The "k2fa" adventitious biases are as follows.
- "k2fa" predicts "false positive," i.e. wrong prediction with a high level of certainty. For example, smiling people or selfie pictures predict as dogs or cats.
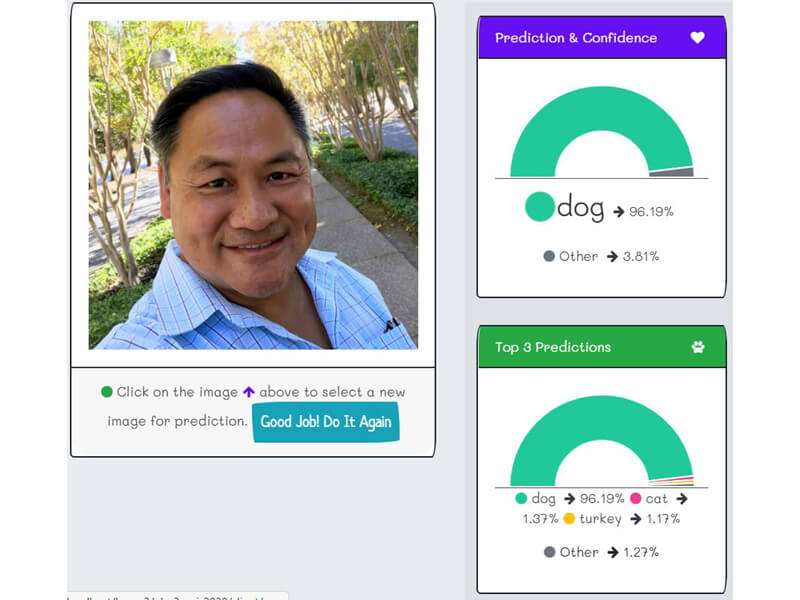
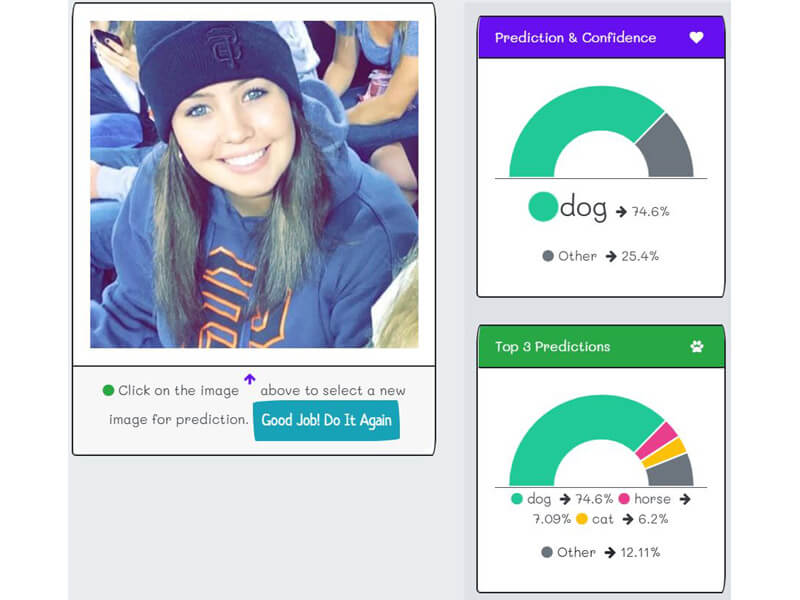
False Positive
- "k2fa" predicts flying ducks as geese.
- "k2fa" predicts any animal or picture shows much lite-skin, pinkness color as pigs. Even for baby pictures.
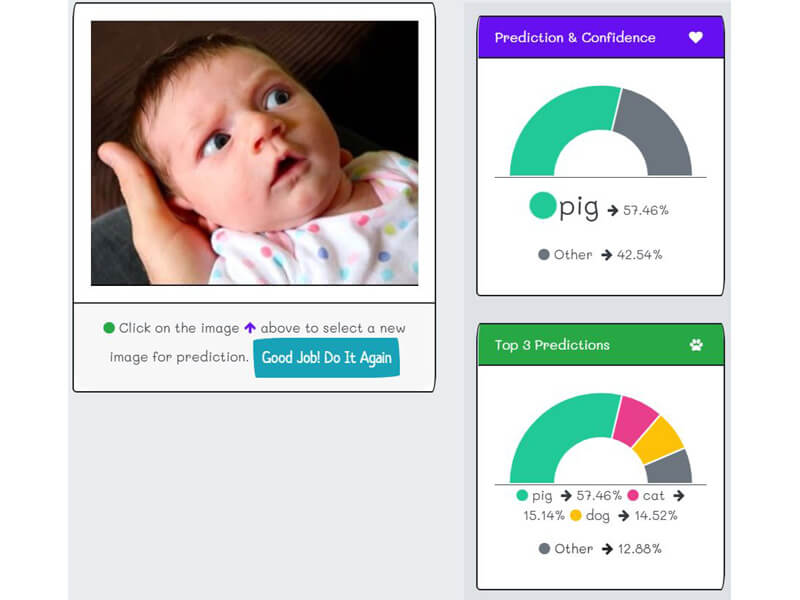
False Positive
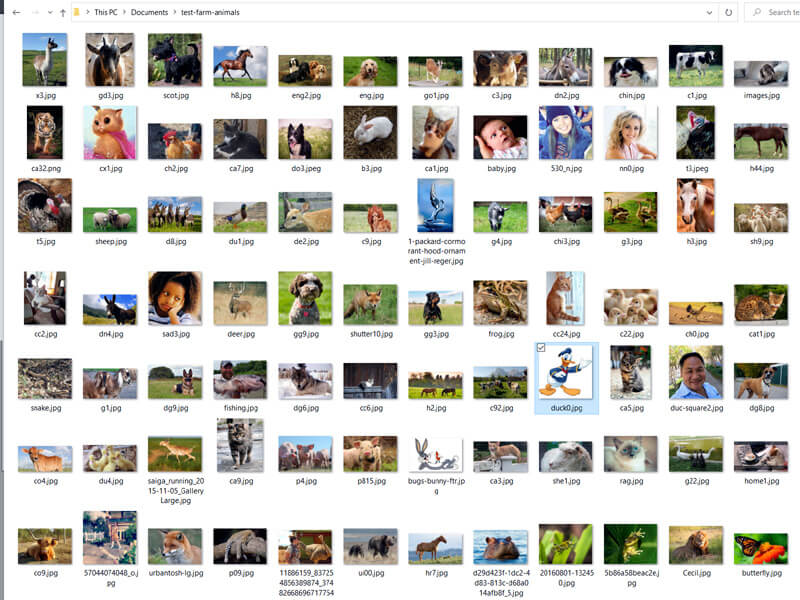
- "k2fa" predicts tigers as horses.
False Positive
- In general, when confronting pictures that were not one of the thirteen farm animals, the desired outcome is uncertainty and not false-positive. "K2fa" does it about 42% of the time.
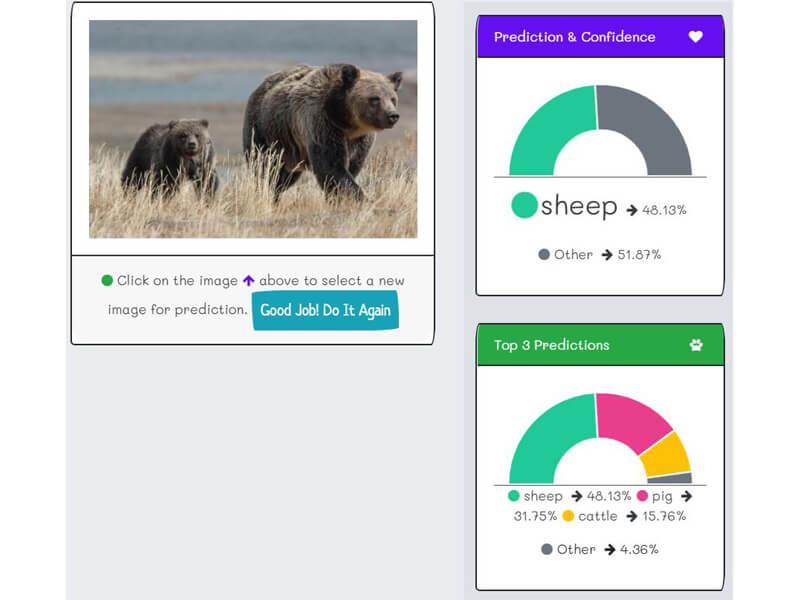
Uncertain (Negative)
Uncertain (Negative)
Use Cases

"Use case" is a consulting terminology for "what are the steps leading to the desired outcome from the user's point of view." For "k2fa," the first "happy path," use-case is as follows.
- Kids download the "k2fa" app on iPhone or Android phones.
- Kids start playing the "scavenger hunt" game with their friends.
- Kids run around a farm, taking pictures of farm animals.
- "k2fa" verifies the farm animal pictures.
- A kid, who has the shortest time finding all thirteen animals, wins the round.

Scavenger Hunt
The second "k2fa" use-case is as follows.
- Kids download the "k2fa" app on iPhone or Android phones.
- Kids start playing the "picture charades" game with their friends, where each player or a team taking pictures of themselves, making faces, paint faces, acting poses, or dress up as the animal. If it is a team, each team member can choose a different animal.
- "k2fa" judges whether the impression passed or failed.
- A kid or team, who has the shortest time, wins the round.

Picture Charades
The use-case's error condition and recovery are for analysts and the QA team to ponder, such as false-positive or cheating, by taking pictures of the online image. As said before, "K2fa" is an anodyne subject, and therefore, there is no known unintentional consequence.
If "k2fa" is in a science fiction story, then "k2fa" could be an army of robots roaming the farm protecting livestock and killing foxes, bears, and coyotes but not tigers. It is because tigers are identifying as "false-positive horses."
The End
The "k2fa" project is a fun journey. I choose it as the first in the series because I have full control, and I can expose each step in the process. It is the same procedure for a momentous AI project, such as "identify people that likely to vote Republicans or Democrats."

More often than not, I have less control over the data, the biases, and the objectives, such as in AI competitions or work projects.
In the second project, we will walk through the same procedure, and I will point out where I have no control. If I could use one of the work projects, you would laugh-out-loud on the preposterous requirements.
The most common one is, "I know that you don't have access to the data or even a data sample, but I want 100% accuracy." My second least favorite is "you must adhere to the team agile methodology in building the AI model and showing it having increase accuracy every two weeks."
On the other side of absurdity, I have been on projects where we discuss AI as a mythical unicorn. The PowerPoint shows in-depth complexity and magical consciousness. If I could do massive matrix multiplication on PowerPoint, then the project is halfway done.
As evidence in the "k2fa" journey, AI is not magically or challenging to build. You do need deep computer science and math knowledge, and it is not from two months of programming boot-camp. Still, it is also true that the data, the biases, the objectives, and the use-cases shape the perceived usefulness of the AI model.
Similar to the social media platforms and mobile app revolutions, we can choose to create AI ethnically or feloniously. However, unlike social transformations, where one can opt-out, AI is shaping the world economy and effecting individual daily life.
For example, "Mr. Jones' insurance will not pay for his recent car accidence." In the USA, it is most likely that an AI renders the decision. Mr. Jones can't opt-out, or he doesn't even know because the human insurance agent did not tell him.
AI systems are powering the world economy, and some are visible like Apple's Siri, but most are not. The salient point is that AI is here, and you can't opt-out.

Duc Haba
Thank you for visiting my project, the "Norwegian Blue Parrot -- K2fa AI model." We are taking the first few steps into the brave new world of AI. The machine consciousness is in the far future and may never come to pass, but AI is transforming our lives in a meaningful way.
From high-tech to manual labor, AI is steadfastly enhancing human intelligence and replacing human workaday tasks and jobs.
I hope you are enjoying the "k2fa" journey, learning something new, and expanding your imaginations. I am looking forward to our next adventure in the "Norwegian Blue Parrot" web series.
You can contact me on my LinkedIn profile.